According to Mr. K the world has been visited by alliens! hahaaaaa =)
back to reality..
Today Mr. K started the class off by introducing us to a new program which he had on his calculator, it is called "TRISOLV2." Providing the program with atleast 3 bits of information, either angles or sides, the TRISOLV2 program can solve the entire triangle. Meaning the program solves the remaining unknown sides or angles.
He then gave us connecting cords for our graphing calculators and he sent the program to some of the students, from there we were to send the program throughout the rest of the class. Once we all had the program on our graphing calculators Mr. K continued on with the lesson.
He first reviewed adding vectors with the class, here is an example..
He first reviewed adding vectors with the class, here is an example..
Find vector A+B
vector A is 6 km east
vector B is 10 km south
These vectors should look as shown below..
1 cm = 1 km


**Remember when using the triangle method the vectors are arranged tip-to-tail.**
The resultant of this vector addition would be the missing vector which connects all the vectors together by creating a triangle (3 sided figure)
1 cm = 1 km
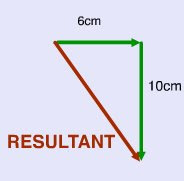

The resultant vector equals 11.66 cm
Next Mr. K gave us another vector addition to solve, we were to use the triangle method aswell. But not just trying to find the length of the resultant vector, Mr. K also showed us how to solve for the angles of the triangle too. Here is the example that he used
Find vector A+B
vector A is 3 m east
vector B is 4 m north
vector A is 3 m east
vector B is 4 m north
1 cm = 1 m
These vectors should look like this..


The resultant vector is shown in the next image
 Using pythagorean theorem as used in the example above, we find the length of the resultant vector as 5 cm.
Using pythagorean theorem as used in the example above, we find the length of the resultant vector as 5 cm.Since the direction of the vector A goes east and vector B goes straight up to north, a 90 degree angle is created.
So the information that we are given all together would be side-angle-side (3cm-90 degrees-4cm)
Therefore, we must use the tri-function inverse TAN to find angle B

Now that we know that angle B equals 53.1 degress we are now able to use the TRISOLV2 program on our graphing calculator to determine the remaining unknown sides and angles of this triangle! All you have to do is open the TRISOLV2 program enter in the 2 sides and the angle into place as labled on the program. (What I mean is make sure that sides a b and c match whats on the diagram above and also the same goes for angles A B and C) Once you have entered in the known sides and angle press solve and the program should look a little somthing like this.

This tells us that angle A = 36.87 B = 53.13 and C = 90
also side a = 3 b = 4 c = 5
I have explained all that I understood and if you have any inputs please tell moi! =)
I CHOOSE KYLE TO SCRIBE NEXT =P













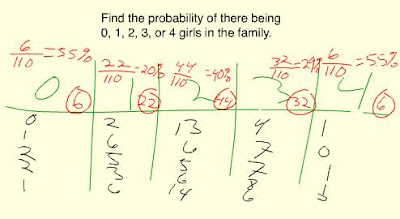 The experiment was done by flipping 4 coins (20 times). Each trial represented one family of four. The probabily for each outcome (0,1,2,3 girls...) was divided by 20 which is the total number of times the experiment was done for.
The experiment was done by flipping 4 coins (20 times). Each trial represented one family of four. The probabily for each outcome (0,1,2,3 girls...) was divided by 20 which is the total number of times the experiment was done for.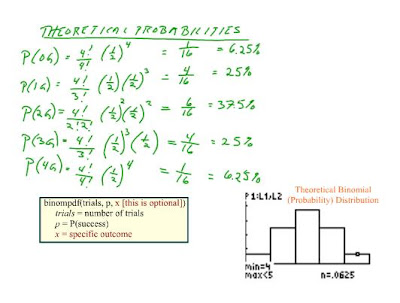









{kind=link}
{kind=link}